
2026年4月AI大模型排名:谷歌登頂,國產模型全面崛起
如果你最近還在用半年前選定的AI模型做業務,可能要重新看一看了。
Artificial Analysis 每72小時更新一次的 LLM 排行榜,目前已收錄 317 個模型。這張榜單不是看論文發表數量,也不靠廠商自報,而是從實際 API 調用中采集智能指數、響應速度、成本和延遲這幾個維度的實測數據。換句話說,它大致反映了”花錢買到的模型到底怎么樣”。
智能指數前五,格局已經變了
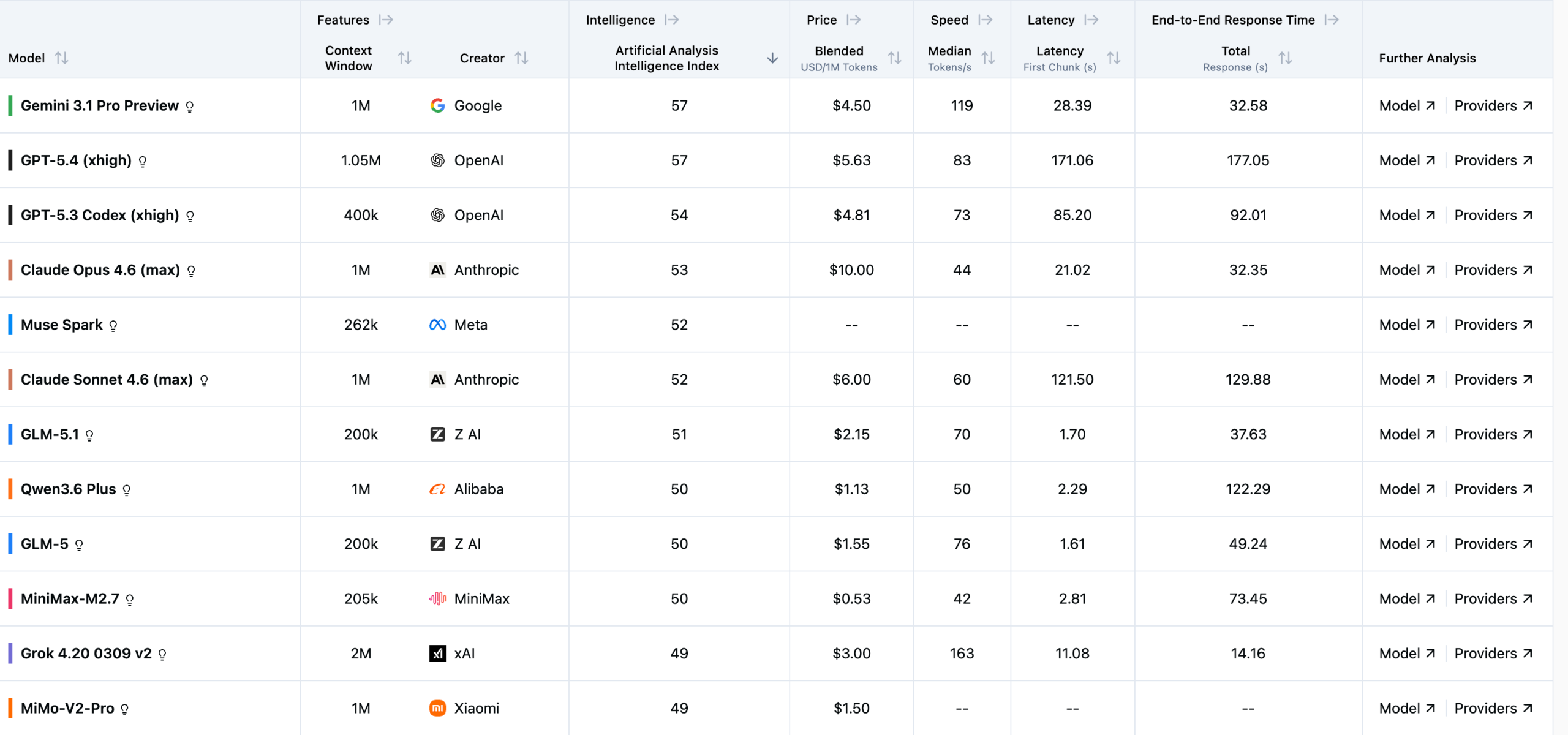
排行榜的核心是”智能指數(Intelligence Index)”,滿分不限,越高越好。截至2026年4月,前五名是:
Gemini 3.1 Pro Preview(谷歌,57分)和 GPT-5.4 xhigh(OpenAI,57分)并列第一,兩家打了個平手。第三是 GPT-5.3 Codex xhigh(OpenAI,54分),第四是 Claude Opus 4.6 max(Anthropic,53分),第五是 Meta 的 Muse Spark(52分)。
值得注意的是,谷歌這次是真正意義上的第一次登頂。過去幾年 GPT 系列幾乎是這類榜單的常客,而 Gemini 3.1 Pro 以實測分數追平 GPT-5.4,說明谷歌在推理能力上已經補上了短板。
Anthropic 的 Claude Opus 4.6 位居第四,但它的定價是每百萬 token 10 美元,在頭部模型里屬于偏貴的。Claude Sonnet 4.6 max 以52分緊隨其后,性價比稍好一些(6美元/百萬token)。

速度榜:誰響應最快
如果說智能指數是”聰不聰明”,那輸出速度決定的是”能不能用”。
目前最快的是 Inception 的 Mercury 2,實測達到 874 tokens/秒,遠超其他模型。第二是 IBM 的 Granite 4.0 H Small(485 t/s),第三是 Granite 3.3 8B(375 t/s)。
這個速度意味著什么?普通閱讀速度大約是每秒4~5個漢字,一個874 t/s 的模型,用來做實時對話完全感覺不到等待。相比之下,Claude Opus 4.6 的速度是44 t/s,差了將近20倍,但它要解決的問題類型本來就不一樣。
延遲方面(首字符時間),阿里的 Qwen3.5 2B 和 Qwen3.5 0.8B 做到了最低延遲,非常適合需要快速響應的實時場景。
最便宜的模型在哪里
價格維度,阿里的 Qwen3.5 0.8B 系列拿下了最便宜的席位,僅需 $0.02/百萬token,基本等于白送。緊隨其后是 Google 的 Gemma 3n E4B($0.03)和 Qwen3.5 2B($0.04)。
DeepSeek V3.2 的價格是 $0.32/百萬token,在同等智能指數水平(42分)的模型里屬于性價比極高的選擇。相比之下,OpenAI 的 GPT-5.4 Pro xhigh 要收 $67.5/百萬token,算是榜單里最貴的,適合對精度要求極高、成本不敏感的場景。
開源模型:國產已經站上主力位置
榜單共有 196 個開源(開放權重)模型,占總數超過60%。
開源模型排名第一的是 GLM-5.1,由智譜 AI(Z AI)發布,智能指數51分,收費僅 $2.15/百萬token。這是中國模型第一次在此類國際榜單的開源分類中拿到第一。GLM-5(50分)緊接其后,Kimi K2.5 以47分位列第三。
除此之外,阿里的 Qwen 系列在這張榜單上幾乎占據了速度、價格、小尺寸模型的多個細分第一,出現頻率相當高。國內還有小米 MiMo-V2-Pro(49分)、DeepSeek V3.2(42分)、百度 ERNIE 5.0、字節跳動 Doubao Seed Code 等多個模型上榜。
一些值得關注的細節
首先是上下文窗口的分化。Meta 的 Llama 4 Scout 和 xAI 的 Grok 4.1 Fast 支持高達 1000萬 token 的上下文,而大多數模型在 128k~256k 之間。對于需要處理超長文檔或代碼庫的應用場景,這個差距會直接影響選型。
其次是推理模型(Reasoning Model)的比例越來越高,目前榜單上有159個推理模型,超過總數的一半。這類模型在輸出前會進行”思維鏈”擴展,在數學、邏輯、代碼等任務上表現明顯更好,但同時延遲也更高——適不適合用,取決于業務場景對實時性的要求。
還有一個趨勢值得留意:越來越多的模型開始追求”小而快”而不是”大而全”。Qwen3.5 0.8B、Ministral 3B、Phi-4 Mini 這些模型在特定任務上的表現已經相當可用,部署成本卻低出一個數量級。
怎么選模型
這張榜單的意義不是告訴你”用最貴的就行”,而是幫你找到你實際需求對應的最優解。
如果你要做復雜推理、深度研究,Gemini 3.1 Pro 或 GPT-5.4 是當前上限。如果是日常對話、內容生成類的業務,Claude Sonnet 4.6 或 DeepSeek V3.2 的性價比更好。如果對速度和成本都很敏感,Qwen3.5 系列幾乎是現在最省錢的選擇。
需要補充的是,智能指數反映的是綜合推理能力,并不等于”對你的業務有用”。具體任務還是要自己跑 benchmark,或者找專門的測評服務驗證。榜單是參考,不是答案。
相關新聞
-
企業合同與客戶信用風險管理系統:打造信用驅動的合同全生命周期風控平臺
企業合同和客戶信用風險管理系統是為企業中高級管理人員和業務管理部門建立的綜合風險控制平臺。系統圍繞“客戶信用”的核心變量,開放合同管理、收款控制、人員證書合規管理和風險預警中心,構建可追溯、可控、可預警的數字風險管理系統。 系統的主要功能包括: 合同全生命周期管理,包括合同的起草、審核、簽訂、暫停、終止、續訂等 客戶信用驅動型收款策略控制,每個客戶都有自己的信用度,信用度會隨著合同的執行情況變化調整 人員與證書合規管理,自動合規驗證和證書生命周期管理 統一風險預警中心 人工智能協助條款風險識別與…
-
Agent Skills與MCP:能力擴展的兩種邏輯與工程實踐
在構建企業級AI智能體的過程中,我們常面臨一個架構選擇:如何處理智能體與外部世界的連接與協作?2024至2025年間,兩種主要范式逐漸清晰——Model Context Protocol(MCP)與Agent Skills。本文將從工程實現與設計哲學層面,解析兩者的本質區別、適用場景與協同模式。 一、問題根源:連接性不等于能力 MCP解決了智能體“能夠連接”的問題。它通過標準化協議(如JSON-RPC)封裝了對外部工具、API或數據源的調用,使智能體能安全地執行如數據庫查詢、文件讀寫等原子操作。…
-
智能問數ChatBI – AI時代的BI報表解決之道
——從傳統BI報表到AI大模型驅動的數據決策升級 在企業數字化轉型不斷深入的背景下,數據已經成為管理層最核心的決策依據。然而,很多企業在實際運營過程中依然面臨一個普遍問題:數據很多,報表很多,但真正支撐決策的內容卻很少。 隨著企業逐步邁入數字化轉型的深水階段,數據已成為經營決策的核心資產。與此同時,AI技術的快速發展正在改變企業獲取和使用數據的方式。過去以“拖拽式”操作為主的傳統 BI報表工具,正在被更加直觀的自然語言交互方式所替代。通過 ChatBI 或 AI問數系統,業務人員無需掌握復雜的數…
-
AI視覺缺陷檢測技術落地方案-塑料注塑件外觀質檢
1. 方案概述 本方案針對塑料注塑件(手機外殼、家電面板、汽車內飾塑件等)的外觀質量管控需求,基于AI視覺+多角度成像+邊緣計算技術架構,實現飛邊、縮水痕、劃傷、頂白、色差、異物六大類缺陷的自動化高精度識別。 其中飛邊、縮水痕、頂白列為嚴重缺陷,執行100%全量檢出標準,杜絕漏檢;劃傷、色差、異物實現精準識別與分級告警,替代人工目視檢測,提升檢測效率、一致性與質量管控水平。 方案采用”頂拍+側拍+背光”三路成像布局,搭配白光、環形同軸光雙光源互補成像,依托邊緣計算盒實現本…
-
各行業人工智能AI應用案例:助力提升2??026年效率
在過去幾年里,人工智能已經悄然成為眾多企業日常運營中不可或缺的一部分。它不再是科技公司專屬的前沿概念,而是切實改變著制造、金融、醫療、零售等傳統行業的運轉方式。這場變革究竟走到了哪一步?企業在哪些場景中真正落地了AI應用?本文嘗試從實際應用出發,梳理幾個最具代表性的領域。 一、從規則自動化到智能判斷:一個根本性的轉變 傳統的自動化工具能做的事情很有限——它們擅長重復、固定的操作,一旦遇到例外情況或需要上下文理解的任務,就會顯得力不從心。而近幾年興起的AI系統則不同,它們能夠從數據中學習規律,理解…
-
AI年代C端和B端還有什么不同?
隨著人工智能技術的快速發展,人工智能正在逐漸打破消費端(C端)和企業端(B端)之間的界限。傳統上,C端和B端一直被視為兩種完全不同的應用系統,在用戶群體、交互技術、產品邏輯等方面存在顯著差異。然而,隨著大型模型技術的興起,C端和B端之間的交互邊界開始變得模糊,未來的人工智能產品將不僅僅分為C端和B端,而是形成一個跨角色和場景的智能服務系統。 C端和B端:歷史上不可逾越的交界線 長期以來,C端和B端都服務于不同的市場需求和用戶類型。C端產品主要面向個人用戶,注重個性化、即時滿意度和完美的使用體驗。…
-
AI時代還需要定制開發軟件嗎
AI大模型正在快速改變軟件生產方式,很多企業開始問同一個問題:既然AI已經能自動寫代碼,為什么還要投入軟件定制開發和系統定制開發?表面看,AI讓開發更快了;但站在企業決策層的角度,真正要解決的不是“能不能寫出代碼”,而是“能不能支撐業務長期增長、穩定交付、可控維護”。 如果你的系統只是一次性工具,標準化產品也許夠用;但一旦涉及多部門協同、復雜流程、數據治理、權限控制、合規要求和未來擴展,AI大模型只能提高效率,不能替代架構設計、業務抽象和工程管理。換句話說,AI時代不是不需要定制開發,而是更需要…
-
AI人工智能體:人類會因為ai大面積失業嗎?
當AI能完成你的工作,誰來為你買單? 近年來,人工智能技術以驚人的速度滲透到各行各業。從自動駕駛汽車到智能客服,從醫療影像診斷到金融風險評估,AI正以前所未有的方式改變我們的工作生態。這種變革引發了一個緊迫的社會議題:人類會因AI大面積失業嗎?本文將深入探討AI對就業市場的真實影響,分析哪些崗位面臨風險,哪些機會正在涌現。 01 哪些工作最容易被AI取代? 不是所有工作都面臨同等風險。研究表明,具有以下特征的工作最易受影響: 1、高度重復性任務:數據錄入、基礎客服、簡單文書處理 2、模式識別類工…
-
AI + 定制系統開發:企業智能化升級的最佳路徑
我們團隊去年幫一家中型企業做了AI升級,過程挺有代表性。關鍵就一條:AI升級不是搞個時髦功能,而是讓系統自己會“看”會“想”。分享下我們走的路徑,很實在。 啟動前先做“體檢”。別急著聊模型,先把客戶所有紙質流程、Excel表格和口頭交接的環節全部挖出來。我們當時發現,客戶的核心痛點是一線工人每天要花3小時填各種表格,管理層第二天才能看到數據。第一個判斷標準就是:這個環節是否依賴人工重復處理信息。如果是,就值得用AI改造。 接著進入“最小可行性閉環”階段。我們從一堆流程里,只挑了一個點:產品質量檢…
-
AI原生嵌入ERP:智能體+大模型正在改變企業管理系統的底層玩法
上個月跟一個做五金配件的老板聊天,他說了句特別實在的話:”我花了兩百萬上ERP,現在最大的感受就是——以前手工記錯賬,現在系統里記錯賬。” 他不是在否定ERP的價值。流程確實規范了,數據確實集中了。但業務員每天花大量時間在系統里錄單、翻菜單、跨模塊找數據,干的全是”伺候系統”的活。ERP本來應該是工具,結果活成了負擔。 這個問題不是個例。很多企業的ERP系統用了五年八年,流程跑得通但效率上不去。不是系統不行,是它太”死”了—…
